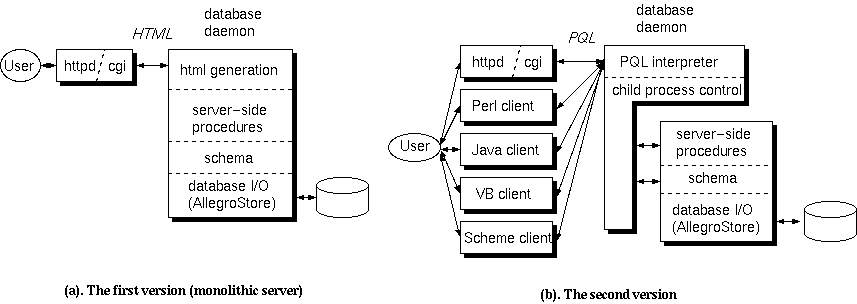
Figure 4. The architecture of Phantom database server. The layered architecture using PQL as a glue worked well for it allowed Bazaar-style development of tools.
Shiro Kawai
Square USA Inc.
55 Merchant St. Ste. 3100
Honolulu, HI., 96813
In early 1997, Square USA opened a studio in Hawaii to produce a full CG feature film, which came to be known as 'Final Fantasy: the Spirits Within'. The project had an ambitious goal---to create photo-realistic human beings. Back then, there were a few full CG feature films in cartoonish style, and people were talking about doing photo-realistic characters, not only as auxiliary effects but as main characters. Some said it would expand the horizon of moviemaking, while some said it was pointless to imitate reality. Anyway, it was clearly a big challenge.
I joined Square in early 1996, and came to the production in late 1997. I worked on designing, building and maintaining asset tracking and production management databases, was involved in the discussion of workflow design, witnessed how the production progressed, and tackled another hidden challenge---to support building a new production from scratch---with a brilliant staff that came from all over the world.
In this paper I discuss the database systems and tools we wrote to solve the problem in Asset Tracking and Production Tracking during the production of 'Final Fantasy'. First, let me define these terms as follows.
Asset Tracking : To track the creation and modification of digital data and information produced during the production. It includes the actual data to create 3D scenes such as geometry, textures or animation data, abstract entities such as sequences and shots, and the auxiliary information such as notes, logs and dependencies between other assets.
Production Tracking : To track who's doing what until when, from individual tasks to the global schedules.
Both require some sort of database system, and actually these two overlap in some areas. For example, shot progress information could be referenced and updated from both sides. However, the 'view' of both sides slightly differed, and mixing these two caused lots of confusion (*1).
I also discuss the problems we faced at the various stages of development of these tracking systems. I should note that the description of events and problems are from my viewpoint as a programmer. Producers and artists participated in the production might have seen different problems and different causes of them.
In the next section I summarize the special characteristics of our production to give you the background ideas. In Section 3 I'll follow the progress of the production and describe the asset tracking and production tracking systems we developed. In Section 4 I'll discuss pitfalls we encountered and lessons we learned from our experience, then I conclude this paper.
Lots of problems we faced were related to certain characteristics of our production. They might not have been problems if the situation differed. To give you better ideas, I'll explain some background characteristics of our production that affected our design of tracking systems.
Our CG studio was not grown from a small core team that shared the same view of working styles; rather, 100 people were gathered and put into a studio(*2). We had lots of talented, experienced people, having various backgrounds. Some came from CG effect houses, some from traditional animation, some from traditional movie industries, and some from academics. They each had different view of production pipeline or even of basic terminology. Nevertheless, we had to take off at once without preparing the "style of our studio".
Furthermore, our goal was something nobody ever had done, so there was no well-established way directly applicable to us. We had to take a trial and error approach, while keeping everybody busy to his/her work. It was surprisingly difficult to form a consensus even on the basic terminology such as shot and element(*3), for the use of them was tightly bound to the person's view of work flow. The confusion persisted until very late stages of the production, despite repeated meetings and published rules. It was partly because, as the production progressed, we found more and more problems that couldn't solve using the previously defined concepts, and kept amending them.
So we had been constantly adjusting data organization (such as directory structures) and workflow organization (such as approval flow). As I describe later, sometimes very basic concepts were changed in middle of the production. If you've done some database work before, you could imagine the mess of changing the basic data relations defined at the time of the database design. However, it was inevitable because of the dynamic nature of the production. What was needed was a system flexible enough to cope with it.
Our staff came from over 20 different countries, but most people spoke English and/or Japanese, so those two were the 'official' communication languages. This environment affected our choice of software platforms; for example, we had to develop tools and web CGI programs that could handle both language (or at least not to break while dealing with Japanese). Some off-the-shelf software packages were excluded from the options because of this. For client side programs we had to make the tools run on both English OS and Japanese OS. Back then, Windows had some nasty incompatibilities between those two versions that bit us many times.
We spent four years from the pilot project to the final film out. It is a long time for the computer-related industry. For example, we used Maya as our main tool, and we started from pre-1.0 release and ended with version 2.5.1. Many other software and hardware needed to be upgraded during the production, and the tools to work with them or to keep track of them needed to be maintained constantly. It is inevitable for a long-term project, but it taxed our development resources severely.
From the viewpoint of the tracking database, another important factor was about people: During such a long period, people came and left. You may be assigned to a task that was handled by somebody who has already left the production. So no information related to former staff could be deleted from the database (*4).
The constant change of people and change of workflow, when combined, made problems much more complicated. You couldn't establish a standard training curriculum if the workflow was changing, for instance.
Apparently simple solution sometimes wouldn't scale to the size of our production. For instance, some production staff loved to use FileMaker Pro to track their work; it is nice software to keep a simple table-type data and publish on the web. However, it wouldn't work when 250 persons started accessing his PC to browse and search the data.
A simple-minded prototype also failed occasionally, for the brute-force approach that worked on a small test data set didn't work on a 'real' production materials. Table 1 may give you some idea of the size of our production (*5).
| Number of shots | 1336 |
| Number of omitted shots | 1427 |
| Number of total frames | 140957 |
| Number of total layers | 28869 |
| Avg. (Max) number of layers per shot | 21.6(130) |
| Number of elements | 43028 |
| Max. disk capacity | 20.7TB |
| Amount of archived data | >50.0TB |
In this section, I describe a series of asset tracking systems we developed along the progress of the production.
Before we went to the real production, we did a few pilot projects to test various technologies. The last test project was to create a short sequence from script and storyboards to the final rendering to verify the workflow. A provisional directory structure and naming convention were defined, and a simple tracking system was developed.
This tracking system didn't use any specific database management system, but relied on the Unix directory structure and text files in it. The system consisted of two parts; a set of Unix commands and Web interface. The Unix commands allowed the artists to check-in and check-out the 3D data, while keeping track of logs. A query command could search the directory structure and log files to give useful information to the managers. The Web system tracked basic data such as shots and cuts, and associated tasks for every artist. The entire system was built in a script language (Scheme) for rapid prototyping. This experience gave us a few insights.
Difficulty of check-in/out workflow: It seemed that it would be difficult to ask artists to follow the strict check-out/check-in workflow, that is, one needed to check-out a file to work on it, then check-in when finished, and during that period the file was locked. This apparently simple concept couldn't be applied in our situation. For example, sometimes the artist wanted to keep several working versions locally to explore different artistic expressions. Our tracking system was not powerful enough to distinguish the "temporary check-in" from the ones that were ready to be rendered, and it prevented the artists from checking in their work casually. Besides that, the performance of the tools were not good for large files and frustrated the users. It was pointed out that the strict locking could be a problem when somebody went home without checking in his work, while the rendering staff found a problem in the current data and needed to fix it (*6).
Frequent change of structure: Query tools depended on the directory structure. In order for them to work, the structure must have been kept in the well-defined, strict rules. However, we needed lots of ad-hoc adjustment to the directory structure, caused the tools to fail, and took time lags to fix them.
Lack of interoperability: Some staff preferred Unix command-line tools, but some didn't know Unix well and needed means to access them from Windows PC. Although a Web CGI interface was provided, it was difficult to make both versions to have the same capability (like editing and searching). Unix command line tools had a flexible pattern matching mechanism to find the elements that matched the criteria (see Figure 1 for examples), but few people used it because of the complexity and slow response.
Search "sample.tiff" in art% pls 'art/**/sample.tiff' art/characters/aki/color/sample.tiff< art/characters/gray/color/sample.tiff Search elements named "gray" % pls '**/gray*' geometry/gray art/characters/gray texture/library/simple_bg/gray1.rgb texture/library/simple_bg/gray2.rgb Show entries of scene "s1", "s3", "s4", "s5", and cut "c5*": % pls 'scene=(s1 s[3-5]):cut=c5*' layout/s1/c5.ma layout/s3/c5.ma layout/s5/c5.ma light/s1/c5.ma |
From the insights of the pilot project, a new design of directory structure and work flow were introduced to the real production. It took over two months of intense discussion to implement the initial version, nevertheless it had to be modified largely later.
The vision of the tracking system at this point was to put the information from the breakdown sheet to the final rendering on-line, and keep track of elements (a group of data files to be delivered as a unit). It was agreed that asset tracking had higher priority to be implemented than production tracking, since without asset tracking artists couldn't work at all. Rigorous directory naming convention was defined so that the elements could be mapped to database entities and vice versa. We dropped the strict check-in/check-out workflow but adopted check-in-only workflow; we thought it'd be enough to keep the history of the production progress.
As for the database, we had realized the necessity of having a commercial- strength database management system. The issue was flexibility, for we had already experienced the redefinition and reorganizations of the data structures. Another concern was that we needed to keep lots of many-to- many relationships, such as characters and shots, artists and sections, elements and assigned artists, and so on. In traditional relational database (RDB) systems, such relationships were somewhat awkward to deal with.
So we looked at object oriented database (OODB) systems. OODB is flexible, leaving developers plenty of room to customize, and extremely easily handle many-to-many relationships. We decided to use Franz Inc.'s AllegroStore, which is an OODB integrated with CommonLisp(*7).
There existed commercial database products for production tracking (one was even built on top of AllegroStore) but we decided to develop our own, for we couldn't foresee if the existing product could fit to our changing demands, even with heavy customization. There were also opinions to reserve room to test nontraditional work flows that may not be supported by the existing products.
It was strongly required that the database could be browsed and edited from both Windows PC (by coordinators) and SGI IRIX machines (by artists), thus we decided to use Web as a primary interface.
This in-house database system was named 'Phantom'. Two programmers spent two months to develop the first version of the database server that could handle HTTP requests as well as socket communications from Unix commands. It was constantly updated. The Figure 2 shows a snapshot of the table structure at this period. The technical details of Phantom system is described in the paper [SK].
| (The figure is missing right now) |
We had several experiences during the development.
Shot/cut debate : This was the incident that showed strength of the customizable OODB. Originally we decided to use two-level hierarchy (sequence/shot) to manage chronological units of the movie, and tools were developed assuming that structure. Then, because of editorial requirements, we introduced a concept of "cuts"; that is, each rendered shot might be cut into one or more "cuts" in the editorial, and multiple shots might be intertwined in the movie. This change required to redefine the frame range of shots, ordering of shots, and some more fundamental stuff. Despite of this change, we could keep the database interface as it had been, by overloading the methods of the shot object, so that the existing tools could keep working. Several months later we decided to drop the concept of cuts since it was too complicated. Again, we could change the database internals keeping the outside interface the same, allowing tools to work without modification.
Data input problem : People envisioned an "on-line breakdown sheet" that could show all the related data about specific shot concisely on the Web. To realize that, however, somebody had to put the information from directors into the database. The Web form has very limited editing capabilities and couldn't catch up with the demand. For example, it was not practical to enter information shot by shot, since sometimes the changes came for several tens of shots. It was convenient for coordinators to use a spreadsheet-type input form, but web browser got unbearably slow for such forms. We eventually added a feature to export/import Excel sheets, although it was an awkward work flow.
Fluid naming convention : As mentioned above, the database operation relied on the fact that all the data files followed well-defined naming convention that the database knew. However, we needed to adjust naming conventions constantly to address the problems in the production pipeline, and the internals of the database had to be adjusted constantly. Occasionally such changes were made locally rather than with global consensus, and the database had to interpret several sets of mutually incompatible rules (*8). Since the database was written in a single monolithic server including the Web interface part, and written in a rather uncommon language Lisp, all of such requests had to go through only one or two programmers, and eventually this became a bottleneck.
No tracking of tasks : It was simply because we didn't have resources to develop the production tracking part of the database. Each element had assigned artist(s), so at least we could track the history of the development. There was a vague plan that the tracking information attached to each element would evolve to the production tracking system. A Number of ideas for task tracking systems were submitted but we always found a case where we couldn't map tasks to elements in reasonable way. We concluded that tasks and elements were independent entities associated with many-to-many relationships, and must be managed differently.
In this first year of the production, we couldn't achieve reasonable productivity.
At this point the studio invited CG line producers to address the production management problems. It required us to change the database development strategy considerably.
The programming bottleneck of the server was because only one or two programmers understood the internals of the database server and could modify it. We needed a way to involve more programmers to develop it, but how?
Some programmers had already asked if they could use SQL to access/modify the database. Unfortunately such interface didn't come with AllegroStore. However, it wasn't very difficult to develop an SQL-like mini-language interpreter in the server(*9).
I implemented such a language we called PQL (Phantom Query Language). It used a Lisp syntax, for simplicity of the parser, but essentially was a subset of SQL. It could actually understand most Lisp expressions so you could write very complex calculations inside a single query (see Figure 3). I also developed Perl client library that could access the database server and retrieve the data as a Perl data structure, so that other programmers could write tools that access the database in their own ways.
;; A form beginning with specific keywords is
;; interpreted as a query.
;; This form lists name, email and sections of
;; users who have email account.
(:select name email sections.name
:from <user>
:where (not (null (email-of this))))
;; The query can be intemixed with Lisp form.
;; This lists each section's name and the number
;; of users in the section
(mapcar #'(lambda (name&users)
(list (car name&users)
(length (cadr name&users))))
(:select name users :from <section>))
;; A reader syntax is extended so that you can
;; directly refer to a specific object using
;; its unique key, using a syntax ?(class key)
(name-of ?(<user> "shiro"))
|
This strategy turned out to work very well. Towards the end of the production, large number of tools were created that accessed the database. In one way, we shifted from Cathedral-style development to Bazaar-style development [ESR]. Anybody who knew Perl could read other database tools, and modify it if necessary (to experiment he could always make his own local version). The diversion of local rules could be covered inside the local group. Eventually other language bindings such as Java and VisualBasic were created (see Figure 4).
Figure 4. The architecture of Phantom database server. The layered architecture using PQL as a glue worked well for it allowed Bazaar-style development of tools.
One big advantage about PQL was that, since we implemented the language parser and interpreter, we could keep the backward compatibility of the queries even we changed the internal schema of the database drastically. We could implement methods to map the old queries to the new schema. This was a tremendous help for us, since we couldn't update all the tools that were accessing the database in timely manner. The statistics showed we changed the database schema in the rate of once a week throughout the period of the production.
One of the reason that the schema changed so much was because the basic working unit of the production changed as the production progressed. In the Layout phase, a "shot" was very abstract concept, since lots of shots were just created/merged/split in order to explore the possibilities of storytelling. Thus structures that required a solid shot definition were not adequate (*10). On the other hand, the later stages of the production, such as Animation and VFX, had clearly shot-based workflow. We had to do Layout stage and the later stages in parallel, and had to find a way to keep these different structures in one database. We split a shot structure into "layout-shot" and "production-shot" internally, while lots of existing tools could view them as just a "shot" object. Late in 1999 when all the Layout work was done, we dropped "layout-shot" structure and merged "production-shot" into "shot". The similar changes happened to the concepts such as "task" and "element" as well.
There was another interesting observation at this point. The directory structure and naming convention were still fluid, and people tended to modify rules to match the workflow of some particular shot or section, and there had been strong objections to enforcing single conventions by, for example, closing the directory permissions of the "checked-in" area. Staff claimed that it would be necessary for them to go into the directory and modify data manually "in case of emergency". However, once tools matured in convenience and robustness, people just used such tools, and started to accept the way the tool asked them to conform. This showed us that, in order to make people follow the rules, there should be tools with which people can work more conveniently, and which people can trust enough.
There was one regretful decision. Since the workflow and structure were changed, and rewrite of the server was required, I dropped HTML support from the server and tried to replace them with Perl CGI scripts using PQL interface. There was some gap before I could provide useful CGIs, and people were very frustrated. Another lesson: once you have provided something, it is difficult to drop the support until you provide superior solutions to it.
In parallel to the back-end database server development, the CG producers asked to develop front-end for them to track tasks. This had to be done on very demanding schedule.
First, the user had to use Windows PC. The producer had FileMaker Pro database she had used in the past productions, and she wanted to have similar screens and operability. Since we had to keep the data in the central back-end database, and FileMaker Pro lacked the ability to use a different database transparently, we had to find alternative. And we had to develop it in a very limited time.
We used Access to create a prototype in a month. All the Access front-end shared a single mdb file on the file server, and a special synchronization script ran periodically to synchronize the PC database and the central back- end database. This wasn't an ideal situation and we had some incidents like one person overwriting changes of another, but it ran fairly well.
After using the prototype for a month or two, we saw it was working and started to develop a PC front-end using VisualBasic, directly communicating to the back-end database to guarantee data integrity between front-end and back-end, and to address some UI issues. Four months later we switched to the new VB version.
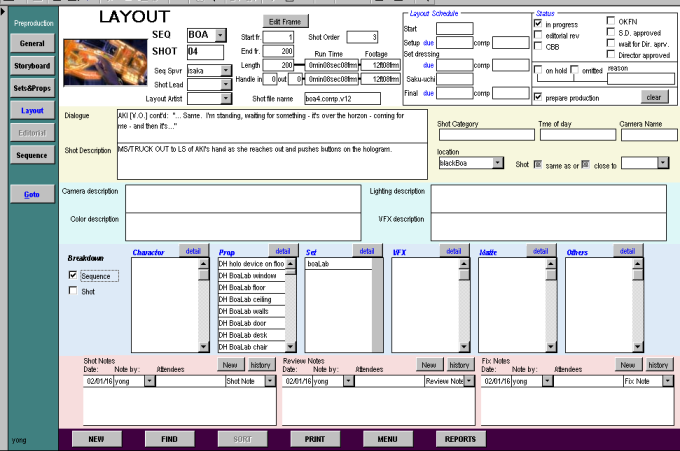
Figure 5. A screenshot of the production tracking database
Unfortunately, one of the CG producers whom we designed the database according to left just around the time the new version was released. The rest of staff were obliged to use the incomplete database without strong incentive to improve it. Consequently, this PC front-end wasn't used extensively throughout the production, although critical parts of the data were kept in it. It showed us a lesson: in order to improve a user interface, you need some user base who is committed to try the incomplete, buggy version patiently, reporting defects and pushing requests to the developers. Otherwise, users just try it out, feel it doesn't satisfy them and keep away from it, or use it "as is" without strong will to improve it.
It was unfortunate that this kind of thing happened a few times. I admit that there was a lot of room to improve the front-end to make it more useful. The users, however, came up whole new ideas for the interface that they thought better for them than the incomplete original. It wouldn't be a problem if we, developers and users, could push the tool up to the point that was feasible for other people to use.
The peak of the production got gradually shifted to the downstream portion of the pipeline, and the rendering team got working really hard to implement a queuing system that could accommodate the production demands.
I modified the back-end database to accept the rendering statistics data from the new queue system. After a while, I noticed that the nature of the statistics data was completely different from the other production data. Statistics data grew monotonically and was hardly ever edited. The amount of the data was huge (by the end of the production, we've got close to 1GB of database containing over 10 million records). The entire search operation over the data took long time, but usually it was OK as such analysis could be done in batch.
I split the database server for statistics data to perform different tuning from the main production database.
The production reached its peak, and saturated the studio's hardware resources. Disk shortage and file server overload became common and the production was screaming.
The database server hit its limit, too, and revealed subtle bugs as well as performance problems. Most of the time I spent tuning the database server. However, the time when database hit its limit and slowed down was exactly the time when the staff didn't want to waste any time waiting for the database response. It was critical to provide enough performance at such peak periods in order to keep user's faith in the system. Unfortunately I failed to provide that, and allowed people to set up their own small databases (from simple text-file to Excel file to the FileMaker Pro).
One such diversion of the database happened like this. There were requests to expand the tracking database to the compositing work, but we didn't have enough time to develop that. A CG producer working for the compositing section created a FileMaker Pro database in order to track the compositing work. As the production work was shifting to the final rendering and compositing, more and more staff were referring to the FileMaker database, and we are required to exchange data between the main database and FileMaker database.
We built a batch process which ran frequently enough to exchange data between two databases, but when both were updating the same data, there was no way to guarantee data integrity. It was bad, but we needed something that worked.
Looking back, I can think of several things I overlooked initially.
Factor in redesign: I estimated the development resources based on the initial design. In an environment where the design is constantly changing, such an estimation is meaningless. You should allocate enough resources to keep up with the production until very end.
Needs of open development: It is absolutely impossible for a single database management guy to know what's going on in the whole studio. The people who know the most current situation are the ones who are working with the artists. So the database architecture has to be open for those developers to implement required functionality in time.
Transparent database: When people first heard about database, it promised lots of things to them, and they were enthusiastic. When the actual database, incomplete version, began working, people started to see it as a burden, requiring extra effort to put data into it, and keeping them from changing things freely. When convenient tools were prepared that accessed databases implicitly, people finally started to feel comfortable. The key is to find the shortest path to the third stage.
Central database = single point of failure: "A single central database" sounds nice, but it is not desirable. There are groups of data that have different characteristics, such as access patterns or frequency of schema change. Examples are shot information and rendering statistics. Some data is very critical and service interruption of such data causes halt of the production, while some data will only be referred to on certain occasions. The optimal database differs depending on the nature of the data, and I don't think it is a good idea to put everything into one unless your production is very small.
Asset tracking and production tracking: I'm still not sure how I can combine these two different views cleanly into one system. Conceptually they look at the same thing from different sides. Asset tracking looks from the view from the elements that are to be delivered, while production tracking looks from the view of the tasks to deliver such an element. However, tasks and elements are not always the same. They tend to have many-to-many relationships, and providing a convenient UI for such relationships is very difficult. (If you have 30 tasks and 30 elements to associate, it is easy. If you have 50,000 tasks and 40,000 elements, I don't know how to do it.)
Around March 2000, when the main production of 'Final Fantasy' was almost over (although the compositing section was busy for the final film out), people started to have meetings to form the effective tracking strategy, directory structures, workflow and databases for the next project. It struck me that the issues discussed there were almost identical to the issues we had discussed three years before.
Creative processes don't have clearly defined paths, for if they have pre- defined procedures, it is just a simple labor rather than a creative process. Therefore, the attempt to give a static definition for such process has to face the tension between divergence towards the creative possibilities and convergence towards the pre-defined mechanical process that databases can handle. That's why the fundamental issues of asset tracking won't change. Finding a balance point is the challenge of asset and production tracking database development.
So how do we differ from where we were four years ago? We learned many lessons, and at least we knew what won't work. I hope this experience will also give you some hints to solve your own problems.
[ESR]
Eric Raymond, "The Cathedral and Bazaar",
http://www.tuxedo.org/~esr/writings/cathedral-bazaar/cathedral-bazaar/.
Also in the book of the same title from O'Reilly, 1999.
[PG]
Paul Graham, "Beating the Averages", 2001.
http://www.paulgraham.com/avg.html
[SK]
Shiro Kawai, "Shooting A Moving Target---An Experience In Developing a
Production Tracking Database", in Proceedings of Japan Lisp User Group
Meeting, May, 2000.
http://practical-scheme.net/docs/jlugm2000.html
(*1) For example, producers wanted to mark the "location" of the shot--- whether the shot is processed in the layout, animation, lighting, VFX or compositing work---while, in the production, the progress of shot was not that pipelined and some sections might be working in parallel on the same shot. So such single notation of "shot location" raised lots of confusions.
(*2) The number of staff went up to 250 at the peak.
(*3) In the visual effect industry, an element is almost the same as an layer, for the artists deliver their work in the form of sequence of rendered images to be composed. Coordinators with that background tend to refer layers as elements. For those who make character models, an element is a set of geometry files, texture files and animation control scripts.
(*4) The database record showed about 350 staff in total in the production, although the peak size of the production was around 250.
(*5) The "number of omitted shots" in the table 1 shows 1427 shots were omitted besides 1336 shots in the movie. It indicates how the changes were common in the production.
(*6) Because of this concern, we had open-permission policy in the file systems until the end of the production, but it caused number of accidents of data loss (overwrite or accidental deletion).
(*7) About using flexibility of Lisp for the server side software, see [PG].
(*8) This kind of local exceptions has to be tolerated, though, for people sometimes needed to try some specific workflow to address an urgent problem (so that they couldn't wait to form global consensus) or to experiment alternative ways before bringing up a global discussion.
(*9) Lisp-family language is good at implementing small language in it.
(*10) For example, attaching information to a shot like who's working on it or what elements are in it seems natural for a shot-based workflow, but you can't precisely enter such information to the database if shots are added, split, merged or removed every day. It d be usefulhe database if shots are added, split, merged or removed every day. It'd be useful to track such information in larger unit at the early stage of the production.