今、そこにある継続
プログラミングの世界の概念には、禅の公案のようなものがある。 それを説明する文章はほんの一文なのに、最初に目にする時、 その文は全く意味をなさない、暗号のように感じられる。 だがひとたびその概念を理解すると、 その概念の説明は確かにその一文で説明されているのがわかるのだ。
そんな、「分かれば分かる」という禅問答の中でも 「継続」は最も謎めいたものの一つと言えるだろう。 文献を紐解くと、 継続とは「これから行われるであろう計算をパッケージ化したもの」とある。 そして、lambdaだらけの説明が後に続くのが普通だ。 実は、分かってしまえばlambdaを使うのが最も正確かつ簡潔な 説明なのだが、分かるまではあまり役に立たない。 ここではまず、多少不正確でも直観的な説明をしてみよう。
|
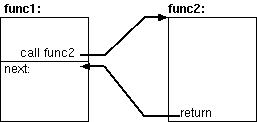
| 図1. func1からfunc2を呼ぶ |
関数func1が処理の途中で関数func2を呼んでいるとしよう。 func2のreturnにより、func1がfunc2を呼んだ 続きから処理が再開される。おそらく多くのプログラマは、図1のようなモデルを 頭に描くのではないだろうか。 (ここでnext:はcallインストラクションの 続きの処理を指すfunc1内のラベルとする。)
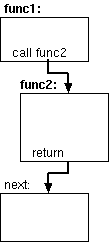
この図をちょいと変形して図2のように描いてみよう。 もちろん本質的には何も変わらないのだけれど、こちらの方が 実際のプロセッサの制御の流れを重視していると言えるかもしれない。 call func2は本質的にfunc2の入口への ジャンプであり、func2の最後のreturnはfunc1内の nextへのジャンプである。ただ、一般にfunc2は色々なところから呼ばれるから、 returnの後にジャンプする先は一定ではない。 func2の呼び出し元(ここではfunc1内のcall func2)が 「returnの後はここに飛んでね」という情報 (ここではnext)をfunc2に渡してやる必要がある。
|
| 図2. func1からfunc2を呼ぶ(2) |
現代のプロセッサの実行モデルに慣れた人なら、callは戻りアドレス をスタックに積み、returnはスタックから戻りアドレスをポップして そこにジャンプする処理だと言うだろう。実は戻りアドレスをスタックに置くというのは、 呼ばれる側に制御の戻り点を伝える方法の一つにすぎない。 別に、call func2の際にnextのアドレスをレジスタの一つに 渡してやったって良いわけだし、メモリの決められた場所に置いておくことにしたって良い。 (もちろん、スタックで渡すのが効率の良い方法だから広く採用されているわけだが)。
上のパラグラフで「戻りアドレス」という言葉を使った。そこには暗黙のうちに、 処理は戻って来るものだというモデルがある。だがプロセッサにとってみれば、 returnからnextへのジャンプはただのジャンプだ。 nextが「戻り」だというのはプログラマの頭に図1のような入れ子呼び出しの モデルがあるからに他ならない。プロセッサの立場から見れば、func2の 呼び出しの処理を次のように言うこともできる:
「call func2は、現在の計算を続行するための情報 を伴ってfunc2にジャンプする。 そしてreturnは、渡された続行地点へとジャンプする。」
この時、「現在の計算を続行するための情報」を継続という。
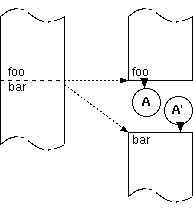 |
| 図3. 処理の切断面としての継続。 A' は Aの継続となる。 |
別の見方をしてみよう。処理をひとつづきのパイプのようなものだと考えて、 どこでも良いがどこかをすぱっと切ってみる。その切り口の下側が上側の継続である(図3)。 必ずしも関数呼び出しの箇所だけではない。ありとあらゆる箇所に、継続は存在する。 ある箇所に関数呼び出しを挿入するということは、処理を輪切りにした上で 下側の継続を伴って呼び出される関数に制御を移すということだ。
したがって、継続とはcall/ccなんていう不思議な呼び出しによって 作られる奇妙な構造ではない。実はどんな言語のどんな処理にも存在していて、 ただそれがプログラマの目に陽に触れないようになっていただけなのだ。 call/ccはその隠された継続をプログラマが扱えるように取り出す処理 なのだが、call/ccの具体例を見る前にもうすこし継続の性質を調べてみよう。
継続の中身
継続は現在の計算を続行するための情報と言ったが、実際にはどんな情報が 必要なのだろう。
もちろん計算を再開するプログラムアドレスは必要だ。 また、func1内で使われているローカル変数等のうち、 next以降でも使われるものは継続に含まれている必要がある (*1)。
さらに、func1そのものがfunc0から呼ばれていたとすると、 next以降の処理が済んだ後でfunc0の継続へとジャンプしなければ ならない。その情報も必要だ。再帰的に、ある継続は、それが作成された時点で 呼び出されている関数についての、実行再開待ちの継続をすべて含んでいなければならない。
一般的な言語の実行モデルでは実行再開アドレスもローカル変数も スタックに積まれるので、継続に必要な情報は全てスタックの中にある。 その場合、継続作成時のスタックポインタを保持しておくだけでも、 限定的に継続を保持することができる。 C言語のsetjmpがやっていることはそれに近い。
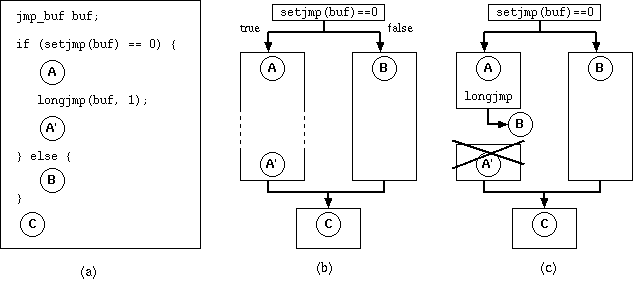
実はC言語のsetjmpは2つの継続を持っている。setjmpが0を返す場合の 継続(A)と、それ以外の値を返す場合の継続(B)だ (図4)。 setjmpは継続(B)をjmp_bufに保存し、継続(A)へと実行を移す。 longjmpはその時点での継続を捨てて、継続(B)へと実行を移す。 longjmpが呼ばれなかった場合、継続(A)と継続(B)はいずれ合流する(継続(C))。 jmp_bufの構造は処理系依存だが、多くの場合、そこにはスタックポインタの値および いくつかのマシンレジスタの値が保存される。
|
| 図4. setjmpとlongjmpを継続を使って説明する。 (a)全体のコード。(b) 式setjmp(buf)==0はコードAへと続く継続と コードBへ続く継続を持っている。 setjmpによりコードBへ続く継続はbufへ保存され、 コードAへ続く継続が実行される。何もなければ両方の継続はいずれ コードCで合流する。 (c) longjmpは本来の継続であるコードA'への継続を破棄し、 コードBへの継続を実行する。 |
setjmpは継続の捕捉の一つの実現方法に過ぎないことに 注意してほしい。setjmpモデルの場合、setjmpによって捕捉された継続は、 スタックがポップされてしまうと無効になる。Schemeの場合は 一度捕捉された継続はいつでも呼び出すことが出来る。 それを実現するためには単純にスタックポインタだけを保存しておくのでは不十分だ。 (Schemeの継続の実装に関しては後で詳しく述べよう)。
現実のプログラムはそれをとりまく外界とやりとりをしなければならないが、 継続が切り取るのはプログラム内部の制御の流れに過ぎない。 例えばプログラムがソケットを開いてネットワークで通信していたとすると、 そのプログラムが保存する継続はあくまでプログラム内部だけのものであって、 その継続を再開した時に通信相手がまだ存在しているかどうかは 継続の知るところではない。同様に、オープンされているファイルとその内部の ポインタや、グローバル変数の値は継続によって捕捉されないとするのが一般的だ。 また、マルチスレッドプログラムにおいて、あるスレッドで捕捉した継続は 別スレッドの動作には影響を与えないとするのが普通である。
但し、言語によってはいくつかのグローバルな状態を継続と一緒に保存する場合がある。 sigsetjmpにおけるシグナルマスクもそうだし、 Schemeではカレント入出力ポートの値や例外ハンドラの値が保存されることもある。 このように、継続が捕まえ得るプログラムの動的な状態を総称して 動的環境 (dynamic environment) と言うこともある。 逆に言えば、ある情報が動的環境に含まれるのならば、それは継続によって捕捉されると言える。
末尾再帰と継続
Schemeでは末尾再帰がgotoと等価であるということを なんでも再帰で述べたが、 継続の考え方を使うと末尾再帰の最適化は自然に導かれる。
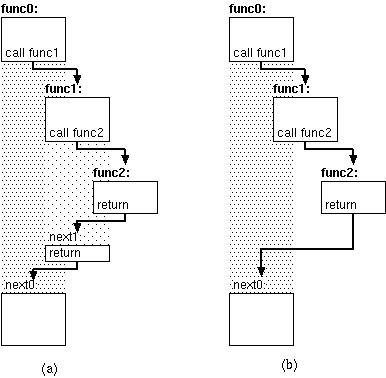
|
|
図5. 末尾再帰の最適化。 (a) func0はfunc1を呼び、func1は 末尾でfunc2を呼ぶ。 (b) func2を呼ぶときにnext0への継続を渡して 直接func2からfunc0へとreturnする。 |
func0がfunc1を呼び、func1がその末尾で func2を呼んでいるというモデルを考えよう(図5a)。 func0は「next0からの継続」を作ってfunc1に渡す。 func1は「next1からの継続」を作ってfunc2に渡す。 ところで、「next1からの継続」というのはreturnのみ、 すなわち「next0からの継続」を呼び出すだけだ。それならいっそのこと、 func1がfunc2を呼ぶ時に、func0から受け取った 「next0からの継続」をそのまま渡してしまったらどうだろう。 func2のreturnは渡された継続へと制御を移すだけだから、 それがnext0であろうとnext1であろうと関知しない。 そのようにすると、実際の制御の流れは図5bのようになる。 これが末尾再帰の最適化だ。 (なお、一般にこの最適化は末尾再帰の最適化と呼ばれるが、 必ずしも呼び出しが再帰している必要はないので、 今後は末尾呼び出しの最適化と言うことにしよう。)
図5bの考え方をさらに進めてみよう。 関数呼び出しとは、継続を渡して関数の先頭へジャンプすることに他ならない。 もし全ての関数呼び出しが末尾呼び出しならば、その呼び出し関係は図1のような 入れ子構造ではなく、全ての処理が数珠つなぎになった形として表現できるだろう。
C言語など、動的環境がスタックに置かれてそれをプログラマから触れない場合は コード上で全てを末尾呼び出しに変換してみせるのは難しいのだが、 Schemeのようにファーストクラスのクロージャがある場合、 継続作成時の環境をクロージャに閉じ込むことで、 コード変換によって全ての関数呼び出しを末尾呼び出しに変えることが可能になる。
与えられた木の全ての葉の数を数える関数leaf-countを考えてみよう。 ここで葉とはペア以外のものすべてとする。最も素直な実装は、木がペアである場合に carとcdrそれぞれの葉の数をleaf-countで数えて 加算し、木がペアで無い場合は単純に1を返すという再帰的アルゴリズムである。
(define (leaf-count tree)
(if (pair? tree)
(+ (leaf-count (car tree))
(leaf-count (cdr tree)))
1))
定義の中で2回呼び出しているleaf-countは末尾呼び出しではない。 どちらも、その戻り値を待って+に渡さなければならないからだ。 ここで、leaf-countをちょっと変えて、木とともに手続きcontを取り、 必ずcontを最後に呼ぶようにしてみよう。 そして、leaf-countの戻り値をそのまま戻すかわりに、 contに渡すようにしてみよう。 呼び出し側は、leaf-countの戻り値を受け取って処理を続けるかわりに、 leaf-countを呼び出す時点の継続を関数の形にしてcontとして 渡すのだ。そのような関数leaf-count/cpsを作ってみよう。
まず、treeがペアでない場合。これは葉なので1を返せば良いが、 「返す」かわりに戻り値を持ってcontを呼び出すことにしたのであった。 ここまでの骨組みはこうなる。
(define (leaf-count/cps tree cont)
(if (pair? tree)
....
(cont 1)))
さて、treeがペアであった場合の処理は次のように分解できる。 便宜上、nとmという変数を新たに導入した。
- (car tree)について葉の数nを数える
- (cdr tree)について葉の数mを数える
- nとmを足したものをleaf-count/cpsの「戻り値」とする
まず最後のステップから見てみよう。「戻り値」はleaf-count/cpsから 素直に戻すのではなく、contに渡すのであった。したがって最終ステップは 次のようになる。
(cont (+ n m))
第2ステップでは、葉の数を数えるためにleaf-count/cpsを 呼ばなければならない。その結果mは、leaf-count/cpsの 第2引数に渡した関数へと渡される (戻り値はcontに渡す、 と決めたことを思い出そう)。 再帰的に呼ばれるleaf-count/cpsのcontとして、 「mの値を受け取り、第3ステップを実行する」という手続きを渡してやれば 目的は達成できる。
(leaf-count/cps (cdr tree)
(lambda (m) (cont (+ n m))))
同じく、第1ステップの結果nを受け取って第2ステップ以降を処理する 動作を手続きに包み込んでやれば、木がペアであった場合の処理が完成する。
(leaf-count/cps (car tree)
(lambda (n)
(leaf-count/cps (cdr tree)
(lambda (m) (cont (+ n m))))))
全てをつなげると、leaf-count/cpsは次のようになる。
(define (leaf-count/cps tree cont)
(if (pair? tree)
(leaf-count/cps (car tree)
(lambda (n)
(leaf-count/cps (cdr tree)
(lambda (m) (cont (+ n m))))))
(cont 1)))
leaf-count/cpsの呼び出しも、contの呼び出しも、 全て末尾呼び出しになっていることを確認して欲しい。
実行して動作を確かめてみよう。leaf-countには素直に 木を渡せば良いが、leaf-count/cpsの場合は一番おおもとの呼び出し元が 最終的な値を受け取るcontを指定してやらねばならない。 一引数の関数ならなんでも良いが、単純にvaluesを渡してやることで、 最後に呼ばれるcontがそのままその値を返すようにしてやることができる。 (valuesがわかりにくければ、displayや printを渡して副作用で結果を見るようにしてもよい)。
(define tree '((a . b) (c . d) . e)) gosh> (leaf-count tree) 5 gosh> (leaf-count/cps tree values) 5
どちらも同じ結果を返す。
末尾呼び出しに変換するのにlambdaが必要なのは、 継続の中で継続が作られる環境にアクセスする必要があるためだ (上の例では、例えばステップ2で参照しているtreeはもともとの leaf-count/cpsに渡されたtreeを参照している)。 環境を捕まえることの出来ないC言語で末尾呼び出しへの変換が 難しいのはそういう理由による。 しかし、限定的な部分ではC言語でも末尾呼び出し的テクニックがコードの 見通しを良くする場合がある。具体例については後に触れよう。
継続を渡して
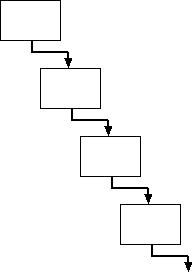 |
| 図6. 継続渡し形式 |
leaf-count/cpsのような形式を、継続渡し形式 (continuation passing style)と呼ぶ。leaf-count/cps内では、 pair?の呼び出しと+の呼び出しは末尾呼び出しになっていないが、 上でやったような操作を全ての関数呼び出しに適用すれば、全ての関数呼び出しが 図6のようなひと続きの鎖になる。
継続渡し形式では、関数からのreturnという概念が無くなる。 呼び出し元が指定した継続contを結果の値を引数として呼び出すことが、 returnと等価になるわけだ(*2)。 関数側から見ると、contは呼んだっきり 戻って来ない手続きに見える (あるいは、関数としては contに結果を渡した時点で使命を終えているので、 contが戻って来ようが来まいが関係無いとも言える)。 この操作を最初の節の関数呼び出しの記述と比べてみよう。 「callとは、継続を伴って関数を呼び出すこと。returnとは、渡された継続へと 制御を移すこと」。 これを文字通り実装しているのが継続渡し形式というわけだ。
計算のアルゴリズムとして、leaf-countとleaf-count/cpsは 等価であり、表現形式が違うだけだということに注意して欲しい。 leaf-countはツリーの深さ分だけスタックを消費するが、 leaf-count/cpsでは全ての再帰呼び出しが末尾再帰だから スタックは消費しない。しかしアクティブなクロージャの数がツリーの深さに 比例するから、リソース消費量のオーダーは結局同じなのだ。 (したがって、非末尾再帰アルゴリズムを単純に継続渡し形式に 変換するだけでは「最適化」したことには必ずしもならない)。
ここで重要なのは、 どんなコードでも継続渡し形式として「見る」ことができる、という事実である。 C言語などクロージャを持たない言語では、コード変換で示すことはできないものの、 例えばある時点でのスタックとマシンレジスタの状態を継続とみなせば、 概念的には継続渡し形式としてコードを解釈することが可能だ。 だから、図3に示したように、どこで切っても金太郎飴のように継続が出てくるのだ。
継続渡し形式は計算の実行のもうひとつの見方だとして、 なぜそんなめんどくさい見方をしなければならないんだろうか。
実は、多くのプログラマは、何らかの形で継続渡し形式を既に使っている。 現実の問題にはよく出てくるのに、 構造化プログラミングでは非常に書きにくいパターンというのがある。 熟練したプログラマなら経験的にそういうパターンを処理していて 敢えて自覚していないかもしれない。 そのようなパターンは、継続を主体に考えると統一的に理解できるのだ。 ポイントは、外部の処理を呼びたいのだが、 呼び出して戻り値を受け取るという形式が使えないケースにある。
例えばユーザインタフェースだ。処理の途中でユーザーに何か 入力を促し、その結果を使って処理を続けたいことは良くある。 しかし多くのGUIプログラミングでは、ユーザーの入力を受け付けるためには 一度GUIのイベントループに戻らなければならない。 したがって、プログラマは 処理をユーザーの入力の前にやる処理Aとユーザーの入力の後にやる処理Bに分けて、
- 処理Aの最後に入力ウィンドウをポップアップし、イベントループに戻る
- 入力ウィンドウの "OK" ボタンが押されるイベントが発生した時に 処理Bが呼ばれるようにする。
という具合にコーディングしているはずだ。 この時、まさに処理Bは処理Aの「継続」なのだ。 (Webアプリケーションにも全く同じ原理が使えることを指摘しておこう。 ユーザーからの入力が必要になった時、Webアプリケーションは一度 入力フォームを吐き出してhttpサーバに制御を戻さなければならない。 「普通のやつらの上を行け」でPaul Grahamが述べているYahoo! Storeの システムはまさにこの技術を実装している。アプリケーションは 継続をクロージャにラップしてセッションIDをキーとするハッシュテーブルに 登録しておき、httpサーバはユーザーからのフォームのsubmitがあると セッションIDを元に登録された継続を呼び出すのだ。)
処理Aと処理Bが複雑なコンテキストを共有しなければならない場合に、 苦労したプログラマも多いのではないだろうか。 例えば再帰的な処理の途中で再帰の深さがある定数を越えた場合に、 ユーザーに「処理を続けるか、止めるか」を尋ねるダイアログを出す、 なんて場合には、再帰の途中経過を自前のデータスタックで管理して おかねばならない。実はその時、あなたは手で継続に相当するものを 作っているわけだ。
また、UNIXにおけるシグナルハンドラの処理を考えてみよう。 ユーザープロセスにシグナルが配送されたことを検知したカーネルは、 ユーザープロセスを中断し、そのプログラムの登録したシグナルハンドラを呼び、 いくつか後始末をしてから中断したプロセスを再開しなければならない。 ここでの問題は、シグナルハンドラはユーザー空間で実行されるということだ。 通常、ユーザー空間とカーネル空間の遷移には特殊なcall/return命令が必要であり、 ユーザー空間のシグナルハンドラから直接カーネルの後始末コードへと returnすることはできない。
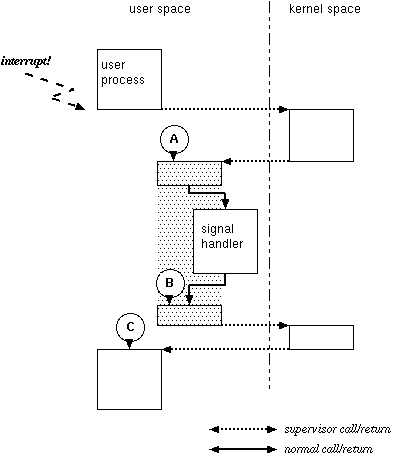 |
| 図7. UNIXのシグナルハンドリング (シグナルトランポリン) |
そこで、カーネルは 「シグナルハンドラを呼ぶ」という継続(図7のA)および 「カーネルに制御を戻してシグナルの後始末をする」という継続(図7のB)を作成し、 継続Bを伴って継続Aを呼ぶ。 中断されたユーザープロセスの継続Cはカーネルが知っており、 コンテキスト情報としてA、Bへと受け渡されて行く。 ユーザー空間でシグナルハンドラを呼ぶための仕掛けである、図7の網かけした 部分はシグナルトランポリンとも呼ばれる。
一般には、関数func1から関数func2を直接呼べない場合に 「func2を呼ぶという継続」をスタックにプッシュして、 func1から一度抜けるテクニックを「トランポリン」と呼ぶ。 func1の呼び出し元は、戻って来て欲しい場所を継続として スタックに置いておいたのだが、func1はその上に 一段ジャンプするクッションを噛ませて、あたかもトランポリンの上で跳ねるようにして func2へと制御を移すわけだ。func2からのreturnは もともとスタックにあった継続、すなわちfunc1の呼び出し元が置いた継続へと 制御を移す。呼び出し元から見れば、あたかもfunc1から直接返ってきたように 見える。
ある種のインタプリタの実装では、ユーザーの提供するCのコードがインタプリタを 再帰的に呼び出すことを許していない。そのようなインタプリタで、 ユーザーの書いたCコードの途中でインタプリタの提供する言語の ルーチンXを呼びたくなった場合にも、トランポリンがよく使われる。 まずユーザーはCのコードをXの呼び出し前(A)と呼び出し後(B)の2つに分割する。 そして、Cコード(A)内で、 まず「returnしたらCコード(B)を呼ぶ」という継続を積み、 その上に「returnしたらインタプリタ言語のルーチンXを呼ぶ」という継続を 積んで、インタプリタへとreturnする。 インタプリタではスタックに積まれた継続に従ってまずXを呼び出す。 Xがreturnしてきたらインタプリタはスタックの次の継続に従って、Cコード(B)を呼び出す。 Cコード(B)がreturnしてきたらインタプリタはその次の継続に制御を移すが、 その継続とはもともとCコード(A)に渡された継続であるというわけだ。
このほか、コンパイラが内部的にプログラムを一度継続渡しスタイルに変換する というテクニックも広く使われている。 コンパイラを書いたことがある人なら覚えがあると思うが、 部分式をコンパイルする時に、 「その値の受けとる場所(レジスタやメモリ、変数等)」および 「受け取る環境(スタックの状態等)」を渡してやるというのは、 概念的には継続渡しスタイルをなぞっていることになる (*3)。
分岐する未来
概念的な話ばかりが続いたが、 実際に継続渡しを明示的に使ってみないとありがたみというのはわからない。 そこで、C言語でも継続渡し的な手法でコードが整理できる例をいくつかあげてみようと思う。
どんなときに継続渡しにするメリットがあるだろうか。 GUIのように処理を中断しなければならない例というのを前節で上げたが、 もう一つ、通常のcall/returnモデルに出来ない、継続渡しの強力な点がある。
call/returnモデルでは、呼んだ関数が戻って来る場所はひとつだ。 しかし継続渡しの場合、複数の継続を渡しておいて、状況によって戻り先(飛び先)を 切り替えることができる。
例えばユーザーインタフェースで、 処理の途中でダイアローグを出してユーザーに入力を促すが、 その後ユーザーが"OK"を押すか"Cancel"を押すかで動作は違ってくるだろう。 この場合、ダイアローグには"OK"を押された場合の継続と "Cancel"を押された場合の継続が存在することになる。
図6のように数珠つなぎの継続渡し方式で、継続が複数ある場合は 一般的な有向グラフとなる。逆に言えば、有向グラフで表せるような 状態遷移型の処理は継続渡し形式で綺麗に書けるのだ。
(予定:Cによる継続渡しもどきの例)
継続を取り出す
(予定:call/ccと簡単な使用例 (non-local exit))
イテレータの反転
(予定:もっと複雑なcall/ccの使用例 (coroutine, interator反転))
第一級の継続の実現
(予定:スタックコピーに関する4つのモデル)
脚注
-
*1: ここで、継続に含まれるのは「変数そのもの」であって「変数の値」ではない。 継続を作成した後でローカル変数の値が書き換えられた場合、計算再開後には ちゃんと書き換えられた値が見えないと困る。
-
*2: 多くの主流の言語では、関数は複数の引数を取り、一つの値を返す。 でも、関数からのreturnと関数の呼び出しが同じ概念なら、 returnに複数の戻り値を渡す (継続に複数の引数を渡す) ってことが 出来ても良さそうじゃないか。その機能は多値と呼ばれ、いくつかの言語には 実装されている。
一つの値しか返せないという言語の制限は、 おそらく値の受け手を複数書けないという言語の構文から来たもので、 実装上の制限ではない。実際にPerlなどのスクリプト言語では 多重代入という名前で疑似的に複数の値を返すことをエミュレートしているし、 一度それを使った人ならC言語で2つ以上の値を得るために変数のポインタを 渡してやらなければならないことをひどく煩わしく感じるだろう。
SchemeとCommonLispは、継続が複数の値を取るという意味での真の多値 をサポートしている (受け手が期待する値の数と渡された値の数が 違っていた場合の処理がSchemeとCommonLispでは違うけど)。 Scheme:多値も参照されたし。
-
*3: 本当に明示的に継続渡しに変換してからコンパイルすることもよくある。 そのあたりは Andrew Appel: "Compiling with Continuations", Cambridge University Press, 1992. に詳しい。